So, I’ve made quite a few posts lately because we are near the time when teachers will be working through the very confusing topic of inferential statistics in Common Core Algebra II. With so little guidance from NYSED on the matter, we are left to sift through sample problems, standards, and (ugh!) the Modules. Ultimately, inferential statistics is a topic that is much, much too large to simply squish into Algebra II.
If anything, the state should almost consider renaming the course Algebra 2 with Statistics if they are honest about the content.
What’s ultimately very difficult is that the CC Standards and the GAISE report for inferential statistics emphasize (in fact insist) on using statistical simulation instead of formulas to develop things such as confidence intervals and margins of error. The theory, at least, is that the formulas are much more understandable (in future courses) if students develop a more intuitive grasp of inferential statistics by using probabilistic thinking generated through simulation.
I’m not sure I even understood what I just typed.
Still, I do get the idea of simulation. If we find that a random sample of 50 people have an average television view time per week of 18 hours per week with a standard deviation of 3.5 hours per week, it is unlikely that the population as a whole has an average view time outside of the interval 17 to 19 hours. Here are the results of running our online simulator where I assume a population mean of 18 with a standard deviation of 3.5 and a sample size of 50. Click on the image to see it more clearly:
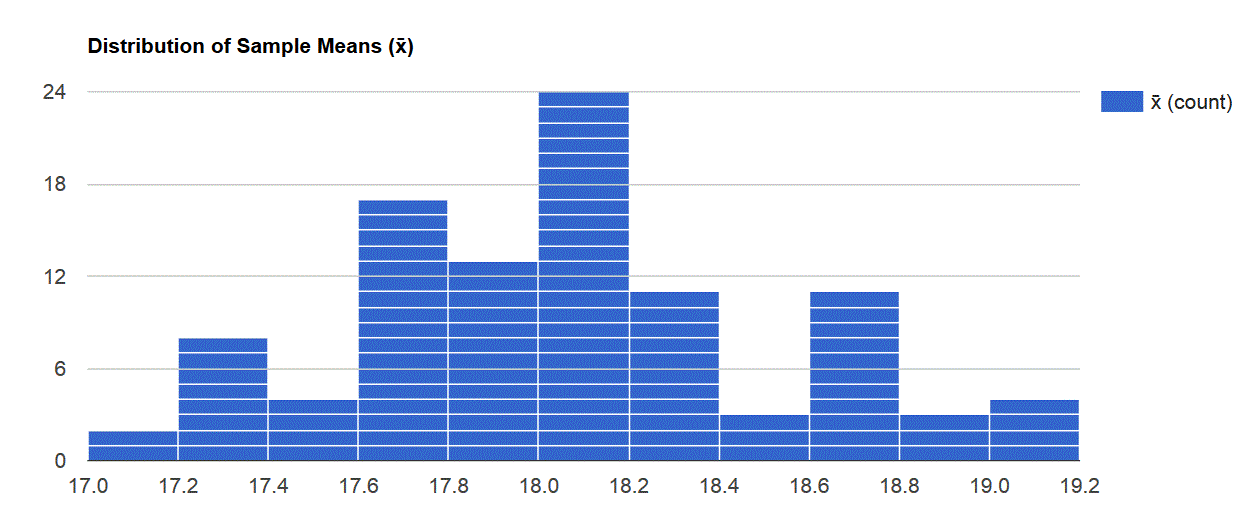
Notice, there are no sample means under this simulation that fall outside of the range 17.0 to 19.2. This, in fact, would be a rough approximation for our confidence interval and half the width between these, i.e. (19.2-17.0)/2=1.1, would be a rough width for our margin of error. By the way, the actual margin of error is a theoretical 0.99 (2*stddev/sqrt(n)). Here’s a link to that simulator and our other two as well:
Sample Normal Distribution Web Based App (NORMSAMP)
Sample Proportion Simulator Web Based App (PSIMUL)
Difference of Sample Means Web Based App (MEANCOMP)
Now, there are more formulaic ways to grind out confidence intervals and margins of error. And, let’s face the fact, the state isn’t going to make them do statistical simulation on the Regents exam (June 1st); what it will do is make them interpret the results of those simulations. I’ve created three new lessons that weren’t in Version 1 of our Common Core Algebra II text. I’ve posted them before, but I’m going to do it again, with the answer keys. Should you spend time on these more formulaic approaches to confidence interval and margin of error? That, I will leave to your professional judgement. I do tie the statistical simulation into these lessons, so that will get reinforced. Here are the lessons and their keys.
CCAlgII.Unit #13.Lesson #8.The Distribution of Sample Means
CCAlgII.Unit #13.Lesson #9.The Distribution of Sample Proportions
CCAlgII.Unit #13.Lesson #10.Margin of Error
CCAlgII.Unit #13.Lesson #8.The Distribution of Samples Means.Answer Key
CCAlgII.Unit #13.Lesson #9.The Distribution of Sample Proportions.Answer Key
CCAlgII.Unit #13.Lesson #10.Margin of Error.Answer Key
Sorry, but no videos on these yet. I am looking to do them before the end of April (so well before June 1st). Maybe consider flipping these or just giving kids the option to watch them and learn the content.
I am so thankful for your materials!
I am working through the statistics lessons now (yes, very short on time) and I would like to just use the web-based simulations so the students can see the results but not worry about running the actual simulations themselves. Maximum understanding with minimum confusion is my goal, in this short time I have left.
I cannot seem to get the MEANCOMP to run as it indicates in the video. I’ve entered the two lists of data into Sample A and Sample B in the DSMSIM but the results are consistently NaN. Can you shed any light on this?
HELP! I am having the same issue and I have no idea why. Can anyone shed some light please?
Thank you so very much!
You bet Jeanne! You need to hit the Add button after you put the data in the box. This is exactly what happened to Amy and I was able to clarify over email what had happened. You must hit the Add button for both sets of data.
I had the same problem because I was typing in the data with just commas. It worked when I used commas and spaces. (11,14 vs 11, 14)
The example given here, like some questions on actual regents, seems to be leaving something out…that is, if you take a sample of 50 people and find the average view time per week is 18 hrs/week, but then you want to know the likelihood that the average viewing time of the whole population is something other than 18, you can’t address that question directly by simulating a bunch of 50-person samples from a distribution that you *assume* has a mean of 18. That answers a different question, which is, “what’s the likelihood that if the whole population actually DOES have a mean viewing time of 18 hrs/week (like the sample) that I might get a different answer if I sampled a different 50 people?” To actually answer the first question, you’d have to assume a distribution with a mean other than 18 (17 or 19, whatever) and see how likely it is that you would get a mean of 18 in a random sample of 50 people. Now, maybe there’s a statistics theorem that says these two questions are equivalent, but intuitively they are not, and i think this is very confusing to students that are new to the subject! Help!!
Phil, I couldn’t agree with you more on so many different points you raise here. Your point is well made. If a sample has a mean of 18, then we should not use a simulation with a population with a mean of 18 to see if we get a sample of 18. We can do a bunch with that sample of 18, including what you suggest, which is to test simulations with means of 17 or 16 or whatever we are interested in and see how likely they are to produce a sample mean of 18. Of course, none of this even gets into the tricky and important subject of what the standard deviation should be of the population based on the sample standard deviation. Mostly, what we have seen on the Regents exams are two different simulations: one where they test how likely a sample proportion would be given an assumed population proportion and then how likely an observed difference in sample trial means is by chance assignment of outcomes to the two treatments. I would say on the whole, though, that the simulation piece of Common Core Algebra II is way to high level and needs to be scaled back in the new standards that are coming out. I think it is a fascinating topic, but too involved for this level of study.
Kirk,
Thanks so much for your comments. I think you have nailed the “core” problem, that the statistics topics being stuffed into Algebra II are too broad and deep to fit. Instead of helping students think critically, it forces them to revert to rote learning so they can give the examiners what they’re looking for. I’m very glad you are out here helping to clarify these things!! it’s a big help to us parents.
Thanks,
–Phil
Phil,
You’re welcome. New York State Ed is right now modifying the standards for all three high school courses/exams and I was hoping they would remove the emphasis on simulations, but it they still appear to be in there. We will be revising our own courses based on these revised standards and hope that we can make our lessons more understandable for students in the years to come. I greatly appreciate your comments as they help us understand better how students (and teachers) are struggling with these very tricky concepts in statstics.
Best regards,
Kirk
Thank you so much for all your materials. They are very helpful. Do you have the answer key for Lesson 8 in Statistics? When I click your link above I get the key for Lesson 9.
Thanks!
I cannot get the normal sample simulation to work. I can only see one graph, the other one is laid on top of it.
Not sure why this is happening. We will have our tech person look at the code and try to have it fixed in the next few days, if not by tomorrow.